動機 #
前一份工作做電商結算系統,曾遇到一個 bug,估且簡化為:所有 H 超商取貨的訂單,都漏向賣家扣取運費。 想當然爾﹐老闆會問:「那麼多訂單費用短收,你們算錢的團隊,是不是應該實時監控一下?」
所以我們就有人花時間去架了個不太好用的監控。監控 50 幾個收費條目在 10 幾個營運國,十分鐘均值有沒有顯著低於一週前。 然後在我離職前這幾百條設定仍未發揮功效…
難點 #
其實 H 超商的訂單佔比不多,運費短收本來就不容易抓。
| 策略 | 結果 |
|---|---|
| 監控每單運費四分位數 | 沒影響 |
| 監控每單運費均值 | 波動小。不及大型家具促銷時,少數高運費訂單增加 |
| 監控有運費的訂單數量 | 雖然有機會抓漏收,但還是抓不到單純短收的情況 |
| 訂單依物流分組,監控均值 | 多半能抓到。但是我們有 50 幾個收費條目,無法逐條工人分類調參數。且不說光物流就有好幾種分類方式(跨國與否、取貨或宅配、貨到付款…)。 |
既然不想分組,就只剩下訂單的運費分佈資訊
| 正常情況下的運費分佈 | 超商漏收時的運費分佈 |
|---|---|
| 多為 0 元 | 0 元訂單微增 |
| 超商店到店在 40 元有一個高峰 | 40 元訂單減少 |
| 存在少數高運費的訂單 | 高運費訂單不受影響 |
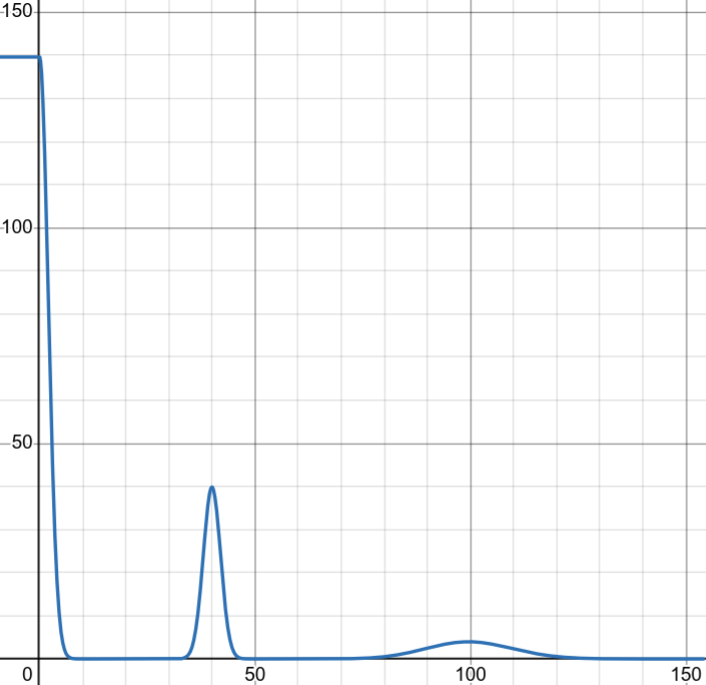
|
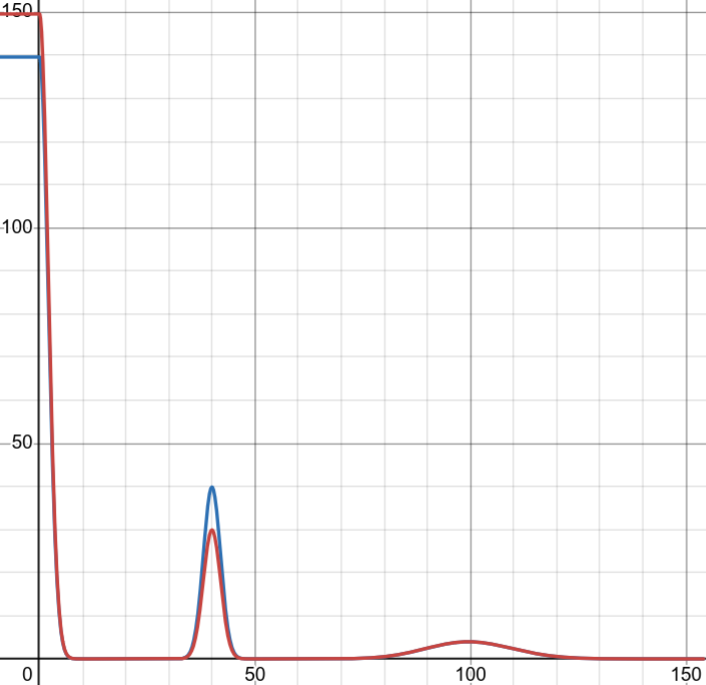
|
他山 #
做推薦系統的 E 曾告訴我,有個專有名詞叫「Distribution Shift(且譯作分佈推移)」,很切合上述現象。
E :「輸入分佈推移時,模型容易表現不佳。換舊版也不見得有用。」
我:「那你們怎麼監控?」
E :「把資料壓成一個維度,然後手切級距分類,看每個分類的數量變化。」
我:「警報的閾值也要手設嗎?」
E :「通常是模型表現不佳,才會看監控釐清原因。不會因為分類計數變化就跳警報。」
ML 教科書也說,整條預測流水線中,監控最後的預測準度比較容易,監控輸入資料的正確性比較難。
總之分佈推移是個有用的概念。手切分類不是。
實作 #
我還沒有實作過,如果讀者有經驗歡迎分享。 下列我認為實作應考量的事。
數值分佈的資料結構 #
一般監控用的時序資料都已對資料進行壓縮。可能壓成直方圖,或是百分位數的估值集(為那些喜歡看 95 或 99 百分位的應用而設計)。有限的樣本經壓縮後,或許有些統計方式就不準了。
如何計算分佈相似度 #
分佈相似度指標隨便找都一大堆。像 KL Divergence、JS Divergence 等… 或許不同情況有各自合適的指標。以運費來說,我希望指標
| 符合 | 因為 |
|---|---|
| 樣本數多和少時,指標的浮動不會差太多 [1] | 別讓訂單數少的營運國經常跳警報 |
| 可以處理數值沒有右界的情況 | 有些國家的幣值低,運費可以上萬;有些國家運費便宜,不是五塊就是十塊 |
| 不需要 D(P, Q) = D(Q, P) 的對稱。最好可以調整指標對左尾和右尾的敏感度 | 有時是要抓短收,有時是要抓多付 |
當然上述幾點都可以強行修正,只是統計意義會變得很難懂。像是
- 固定回溯 100 個樣本來描述當下的分佈
- 用更長的歷史數據正規化各國的運費
- 把數值取對數(或任何非線性變換),消彌右尾變化率的影響
適用情況 #
其實分佈推移的概念,更適合應用在持續性的指標,而非數量起伏的樣本。例如機器的記憶體使用率就很合適。因為
- 機器的數量固定,沒有樣本集要回溯多少的問題。
- 數值就是 0-100%,通常也不會被壓縮。
- 顯然是要抓某類機器的記憶體使用率的上升,下降不是那麼重要。
分佈推移的概念,顯然比傳統 p90 或 top5 更適合監控多機器的記憶體使用變化。
唯一缺點是分佈推移只能描述相對變化,不能拿來當 auto scaler 要 scale 多少的絕對指標。硬要的話只能設定一個理想分佈跟它取相似度了。
| 平常記憶體使用率 | 大量機器使用率上升 | 少量機器使用率暴漲 |
|---|---|---|

|
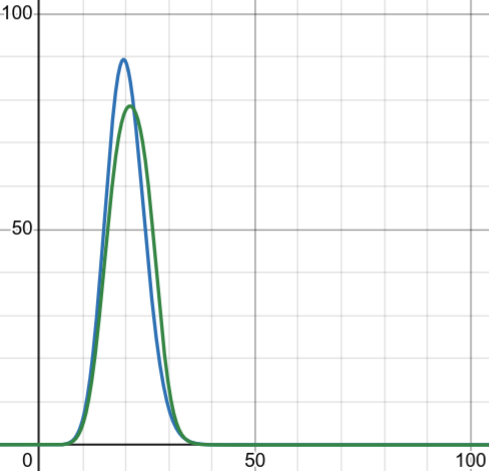
|
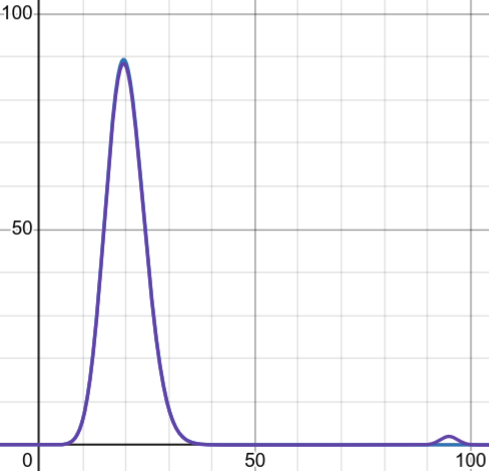
|
結論 #
或許分佈推移的概念,可以用在監控上吧。
[1] 這裡要引用的文章我還沒寫好QQ